The Java PDF OCR module available in Qoppa PDF libraries currently runs on Tesseract 3.02. In June 1st 2017, Tesseract 3.05 was released and as a part of our 2018 software release cycle, we looked into upgrading the OCR module to use that version.
Tests were done to compare Tesseract 3.02.02 against the new 3.05.01 engine using our in house OCR test suite containing 96 documents. These documents contain a mix of scanned documents having various content types, font, quality, rotation/skewing, and page counts. PDFs were converted to uncompressed grey scale images at 300 DPI and sent to the Tesseract engine.
It has to be noted that we evaluated the OCR accuracy by analyzing and comparing the resulting PDF documents (with inserted OCRed text) visually. The invisible text was changed to be made visible and we used the PDF overlay comparison feature available in our end-user tool PDF Studio to overlay and compare the documents.
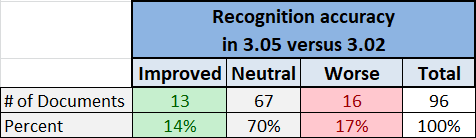
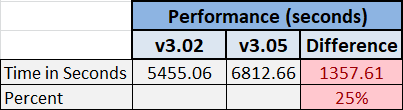
We found that Tesseract version 3.05 was less accurate and slower than version 3.02 for our test case and our test suite.
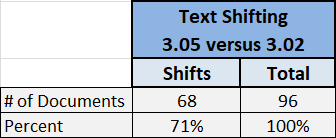
We also found that for a large majority of documents, the hCOR objects would return shifted text location when compared to the previous version, for the worse. Sometimes the text shift was slight, only by one or 2 pixels off. But for many PDF documents, a single line on the page, with font size and text similar to other lines on the page, would be shifted by a lot more. Considering this was random and variable, it would have been difficult to adjust our code – to insert the text into the PDF documents – to cancel / offset this difference.
After evaluating Tesseract version 3.05 and finding that version 3.02 was superior for our purposes, we decided to continue shipping with version 3.02 in Qoppa Java PDF OCR Library SDK.
Comparing Tesseract version 3.05 to version 3.02
Test Results Summary
Full test results can be downloaded here OCR Results (Combined).xlsx
